Manus Invitation Code Application Guide
1083
English
Recently, an advanced text-to-speech system called Spark-TTS has sparked widespread discussion in the AI community. According to the latest X posts and related research, the system stands out with its zero-sample voice cloning and fine-grained voice control capabilities, demonstrating a major breakthrough in the field of speech synthesis.
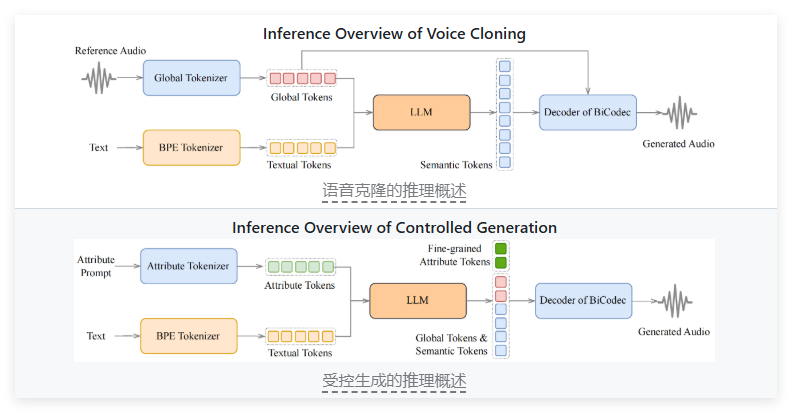
This system takes full advantage of the powerful capabilities of large language models (LLMs) and is committed to achieving highly accurate and natural speech synthesis for both research and business. Spark-TTS' design philosophy emphasizes simplicity and efficiency. The system is completely built on Qwen2.5, abandoning the complex process that required additional generative models in the past. Unlike other models, Spark-TTS reconstructs audio directly from LLM predicted code, an approach that greatly simplifies the steps of audio generation, improves efficiency and reduces technical complexity.
In addition to efficient audio generation capabilities, Spark-TTS also has excellent voice cloning capabilities. The system supports zero-lens voice cloning, which means that Spark-TTS can successfully copy speaker voice even without training data for specific speakers.
The core features of Spark-TTS include:
Zero sample voice clone: generates its voice style without the training data of a specific speaker, suitable for fast personalized applications.
Fine-grained voice control: Users can accurately adjust speech speed and pitch, such as speeding up or slowing down speech, changing the sound height.
Cross-language generation: Supports multiple languages, including English and Chinese, extending its applicability worldwide.
Its voice quality is considered very natural and is particularly suitable for audiobook production, which is proven in user feedback.
Technical Architecture
The technical basis of Spark-TTS is the BiCodec single-stream voice codec. This codec breaks down speech into two markers:
Semantic markers with low bit rate are responsible for language content.
Fixed-length global markers responsible for speaker attributes.
This separation method allows for flexible adjustment of speech characteristics, and combined with Qwen-2.5's Chain-of-Thought technology, further improving the quality and controllability of speech generation. Qwen-2.5 is a large language model (LLM) that provides it with powerful semantic understanding capabilities.
Spark-TTS is also excellent in language support. It is able to process both Chinese and English and maintain high naturalness and accuracy when synthesized across languages. In addition, users can also create a virtual speaker that meets their needs by adjusting the gender, tone, and speech speed of their voice.
Project: https://github.com/SparkAudio/Spark-TTS








