
Manus邀請碼申請攻略
1085
中文(繁體)
日前,一款名為Spark-TTS 的先進文本轉語音系統引發了AI 社區的廣泛討論。根據最新的X 帖子和相關研究,這款系統以其零樣本語音克隆和細粒度語音控制能力脫穎而出,展現了語音合成領域的重大突破。
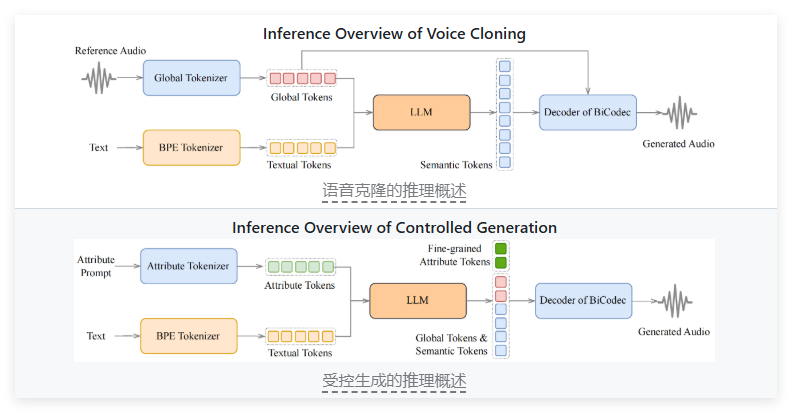
這款系統充分利用了大型語言模型(LLM)的強大能力,致力於實現高度準確且自然的語音合成,適用於研究和商業領域。 Spark-TTS 的設計理念強調簡潔與高效。該系統完全基於Qwen2.5構建,摒棄了以往需要額外生成模型的複雜流程。與其他模型不同,Spark-TTS 直接從LLM 預測的代碼中重建音頻,這種方法極大地簡化了音頻生成的步驟,提高了效率,降低了技術複雜度。
除了高效的音頻生成能力,Spark-TTS 還具備出色的語音克隆功能。該系統支持零鏡頭語音克隆,這意味著即使沒有針對特定說者的訓練數據,Spark-TTS 也能成功複製說話者的聲音。
Spark-TTS 的核心功能包括:
零樣本語音克隆:無需特定說話者的訓練數據即可生成其聲音風格,適合快速個性化應用。
細粒度語音控制:用戶可以精確調整語速和音高,例如加快或放慢語速,改變聲音高低。
跨語言生成:支持多種語言,包括英語和中文,擴展了其在全球範圍內的適用性。
其語音質量被認為非常自然,特別適合用於有聲讀物製作,這一點在用戶反饋中得到了證實。
技術架構
Spark-TTS 的技術基礎是BiCodec 單流語音編解碼器。這種編解碼器將語音分解為兩種標記:
低比特率的語義標記,負責語言內容。
固定長度的全局標記,負責說話人屬性。
這種分離方法允許靈活調整語音特性,同時結合Qwen-2.5的思維鏈(Chain-of-Thought)技術,進一步提升了語音生成的質量和可控性。 Qwen-2.5是一種大型語言模型(LLM),為其提供了強大的語義理解能力。
在語言支持方面,Spark-TTS 同樣表現出色。它能夠同時處理中文和英文,並在跨語言合成時保持高自然度和準確性。此外,用戶還可以通過調整語音的性別、音調和語速等參數,創建出符合自己需求的虛擬說話人。
項目:https://github.com/SparkAudio/Spark-TTS







