Manus Invitation Code Application Guide
1092
English
In the field of artificial intelligence, training of large language models (LLMs) has become an important direction to promote technological progress. However, as the model size and data sets continue to expand, traditional optimization methods—in particular AdamW— have gradually revealed their limitations. Researchers face a series of challenges such as high computational costs and instability in training, including gradient disappearance or explosion, inconsistent parameter matrix updates, and high resource requirements in distributed environments. Therefore, more efficient and more stable optimization techniques are urgently needed to deal with these complexities.
To address these challenges, Moonshot AI (Dark Side of the Moon) and UCLA jointly developed Moonlight, a Mixture-of-Expert (MoE) model using the Muon optimizer. Moonlight provides two configurations: one is the activation parameter is 3 billion, and the other is the total parameter is 16 billion, and 5.7 trillion marks were used for training. The innovation of the Muon optimizer lies in the use of the Newton-Schultz iterative method to perform matrix orthogonalization to ensure the uniformity of gradient updates in the model parameter space. This improvement provides a promising alternative to traditional AdamW, improving training efficiency and stability.
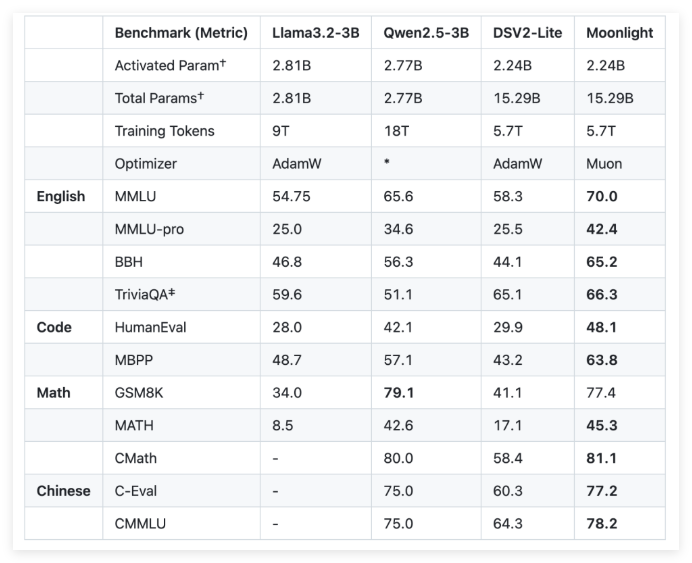
In terms of technical details, Moonlight made two key tweaks to the Muon optimizer. First, weight decay technology is introduced to control the growth of weights during training of large models and large markers. Secondly, the update amplitude of each parameter is calibrated so that it is scaled according to the square root of the maximum dimension of the weight matrix, thereby achieving consistency of updates.
Through an empirical evaluation of Moonlight, the researchers found that its performance at intermediate checkpoints was better than the traditional AdamW training model. For example, in the language comprehension task, Moonlight earned higher scores on the MMLU benchmark. In code generation tasks, the performance improvement is more obvious, indicating that Muon's optimization mechanism has positively contributed to task performance.
The successful implementation of the Moonlight project will bring new standards to the training of large language models. The open source implementation of the Muon optimizer and the release of pre-trained models and intermediate checkpoints are expected to facilitate further research on scalable optimization techniques.
github:https://github.com/MoonshotAI/Moonlight?tab=readme-ov-file
huggingface:https://huggingface.co/moonshotai/Moonlight-16B-A3B
Paper: https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf








