Meta launches new AI chatbot features: actively sending messages to improve interactive experience
1788
English
In recent years, significant progress has been made in large language models (LLMs) based on the Transformer architecture, with new models such as Gemini-Pro1.5, Claude-3, GPT-4, and Llama-3.1 capable of handling hundreds of tokens.
However, the context lengths of these extended pose some significant challenges in practical applications. As the sequence length increases, the decoding delay increases, and memory limits also become a serious bottleneck. KV cache stores context information during inference. As the context length increases, the cache size also increases proportionally, which leads to memory saturation, which seriously affects the efficiency of processing long input sequences, so optimization solutions are urgently needed.
While there are some training-free methods on the market, they often rely on getting attention weights to determine the importance of key-value pairs, which makes them incompatible with efficient attention algorithms such as FlashAttention. These methods often require partial recalculation of the attention matrix, introducing time and memory overhead. Therefore, existing compression algorithms are mainly used to compress prompts before generating answers, rather than optimization in memory-constrained generation. This limitation emphasizes the need to develop compression technologies that can maintain model performance without requiring architectural modification.
A team from the Sorbonne University, the French National Institute of Information and Automation, the University of Sapinza, the University of Edinburgh and Miniml.AI have proposed Q-Filters, a powerful training-free KV cache compression technology that utilizes query-based filtering to optimize memory usage while maintaining model performance. Q-Filters evaluates the importance of key-value pairs associated with the current query, rather than relying on attention weights. This approach ensures compatibility with efficient attention algorithms without retraining or architecture modification. By dynamically evaluating and retaining the most relevant contextual information, Q-Filters achieves significant memory reduction while maintaining the quality of reasoning.
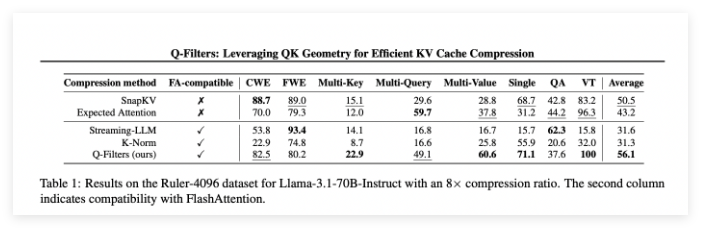
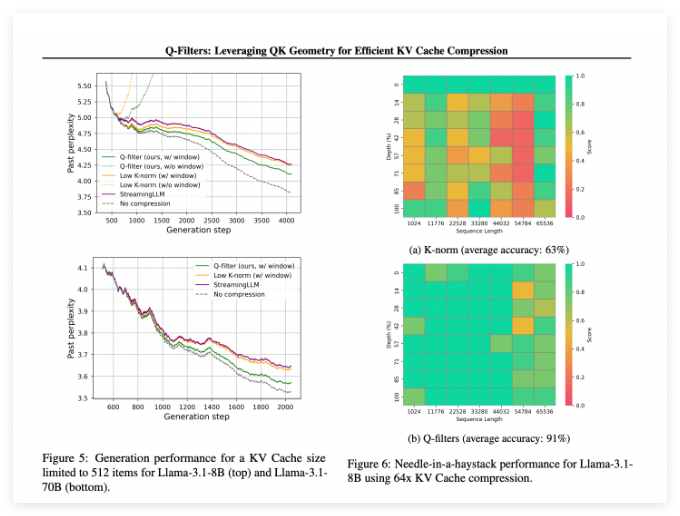
Q-Filters performs well in multiple evaluation scenarios and always outperforms existing KV cache compression methods. In language modeling testing of Pile datasets, this technology achieves the lowest level of confusion in all compression schemes. Especially on the Llama-3.1-70B model, Q-Filters showed significant reduction in confusion in the second half of the sequence where context retention was critical.
In the Needle in Haystack task, Q-Filters maintained 91% accuracy, successfully saving important information in extreme context lengths (from 1K to 64K tokens). The comprehensive evaluation also verified the superiority of the method, especially at high compression rates (32 times), with Q-Filters achieving the highest score in the long context modeling benchmark.
Paper: https://arxiv.org/abs/2503.02812
huggingface:https://huggingface.co/collections/nthngdy/q-filters-67a4994dcb302a3d37f3d119