
Manus邀請碼申請攻略
1081
中文(繁體)
近年来,基于 Transformer 架构的大型语言模型(LLMs)取得了显著进展,诸如 Gemini-Pro1.5、Claude-3、GPT-4和 Llama-3.1等新模型能够处理成百上千的token。
然而,这些扩展的上下文长度带来了实际应用中的一些重大挑战。随着序列长度的增加,解码延迟上升,内存限制也成为了一个严重的瓶颈。KV 缓存在推理过程中储存上下文信息,随着上下文长度的增加,缓存的大小也呈比例增长,这导致内存饱和,严重影响了处理长输入序列的效率,因此迫切需要优化解决方案。
虽然市场上存在一些无训练的方法,但它们通常依赖于获取注意力权重来确定键值对的重要性,这使其与高效的注意力算法(如 FlashAttention)不兼容。这些方法往往需要对注意力矩阵进行部分重新计算,从而引入了时间和内存开销。因此,现有的压缩算法主要用于在生成答案之前压缩提示,而非优化在内存受限的生成过程中。这一局限性强调了需要开发既能保持模型性能又不需要架构修改的压缩技术。
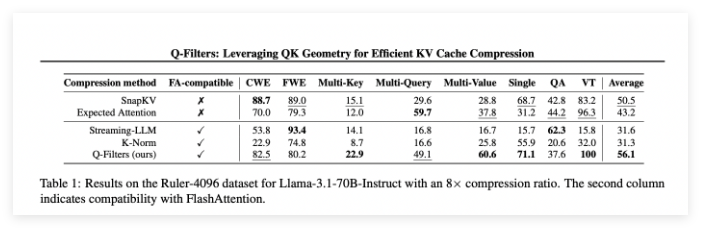
来自索邦大学、法国国家信息与自动化研究所、罗马萨平扎大学、爱丁堡大学和 Miniml.AI 的研究团队提出了 Q-Filters,这是一种强大的无训练 KV 缓存压缩技术,利用基于查询的过滤方法来优化内存使用,同时保持模型性能。Q-Filters 通过评估与当前查询相关的键值对的重要性,而不是依赖于注意力权重。这种方法确保了与高效注意力算法的兼容性,且无需重新训练或修改架构。通过动态评估并保留最相关的上下文信息,Q-Filters 实现了显著的内存减少,同时维持了推理质量。
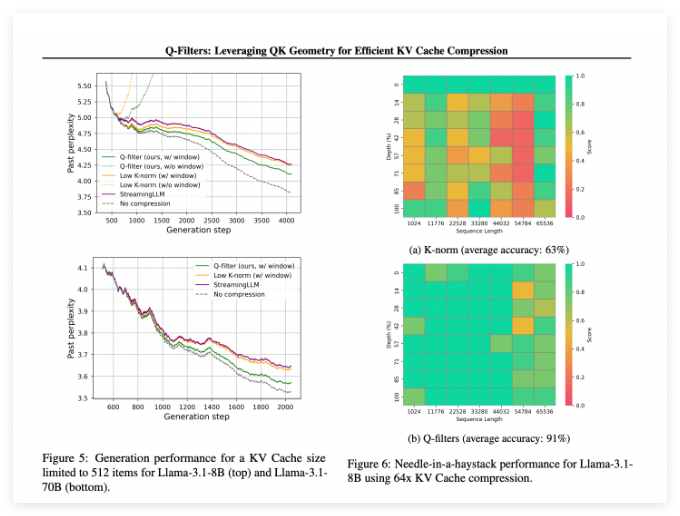
Q-Filters 在多个评估场景中表现出色,始终优于现有的 KV 缓存压缩方法。在对 Pile 数据集的语言建模测试中,该技术在所有压缩方案中实现了最低的困惑度。特别是在 Llama-3.1-70B 模型上,Q-Filters 在上下文保留至关重要的序列后半部分显示出显著的困惑度降低。
在 “针在干草堆” 任务中,Q-Filters 保持了91% 的准确率,成功地保存了极端上下文长度(从1K 到64K token)中的重要信息。综合评估还验证了该方法的优越性,尤其是在高压缩率下(32倍),Q-Filters 在长上下文建模基准测试中取得了最高分。
论文:https://arxiv.org/abs/2503.02812
huggingface:https://huggingface.co/collections/nthngdy/q-filters-67a4994dcb302a3d37f3d119







