Manus Invitation Code Application Guide
1092
English
Recently, Google announced the launch of a new vision-language model (VLM), called PaliGemma2Mix. This model combines the capabilities of image processing and natural language processing, can understand visual information and text input at the same time, and generate corresponding outputs based on needs, marking a further breakthrough in artificial intelligence technology in multitasking.
PaliGemma2Mix is very powerful. It integrates a variety of visual-language tasks such as image description, optical character recognition (OCR), image question and answer, object detection and image segmentation, and is suitable for a variety of application scenarios. Developers can use this model directly through pre-training checkpoints, or further fine-tune according to their needs.
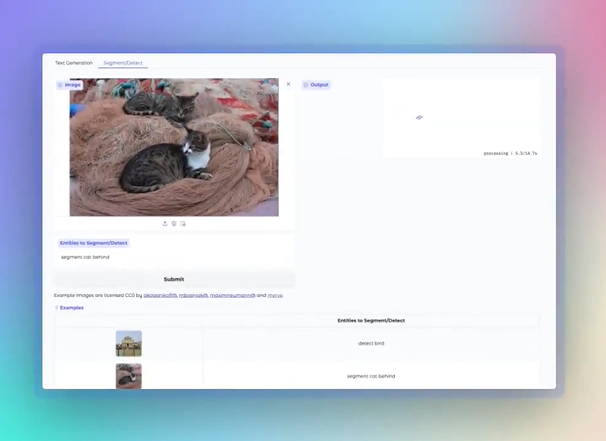
Optimized based on the previous PaliGemma2, this model has been specifically tuned for hybrid tasks, designed to allow developers to easily explore their powerful abilities. PaliGemma2Mix provides three parameter scales for developers to choose from, including 3B (3 billion parameters), 10B (10 billion parameters) and 28B (28 billion parameters), and supports two resolutions: 224px and 448px, adapting to different computing resources and task requirements. .
The main features of PaliGemma2Mix include:
1. Image description: The model is able to generate short and long image descriptions, such as identifying a picture of a cow standing on the beach and providing a detailed description.
2. Optical character recognition (OCR): This model can extract text from images, identify logos, labels and document content, and provide convenience for information extraction.
3. Image Q&A and object detection: Users can upload pictures and ask questions, the model will analyze the pictures and give answers. In addition, it can accurately identify specific objects in the image, such as animals, vehicles, etc.
It is worth mentioning that developers can download the mixed weights of this model on Kaggle and Hugging Face for further experiments and development. If you are interested in this model, you can explore it through Hugging Face's demonstration platform to understand its powerful capabilities and application potential.
With the launch of PaliGemma2Mix, Google's research in the field of vision-language models has taken another step forward, and we look forward to this technology to show greater value in practical applications.
Technical report: https://arxiv.org/abs/2412.03555








