
Manus邀請碼申請攻略
1092
中文(繁體)
近日,谷歌宣布推出一款全新的視覺- 語言模型(Vision-Language Model, VLM),名為PaliGemma2Mix。這款模型融合了圖像處理與自然語言處理的能力,能夠同時理解視覺信息和文本輸入,並根據需求生成相應的輸出,標誌著人工智能技術在多任務處理方面的進一步突破。
PaliGemma2Mix 的功能非常強大,它集成了圖像描述、光學字符識別(OCR)、圖像問答、目標檢測和圖像分割等多種視覺- 語言任務,適用於多種應用場景。開發者可以通過預訓練檢查點(checkpoints)直接使用這款模型,或根據自己的需求進行進一步微調。
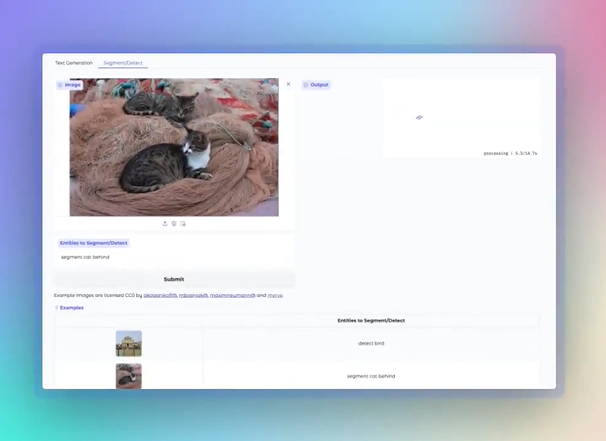
該模型是基於先前的PaliGemma2進行優化而來,專門針對混合任務進行了調整,旨在讓開發者輕鬆探索其強大的能力。 PaliGemma2Mix 提供三種參數規模供開發者選擇,包括3B(30億參數)、10B(100億參數)和28B(280億參數),並支持224px 和448px 兩種分辨率,適應不同計算資源和任務需求。
PaliGemma2Mix 的主要功能亮點包括:
1. 圖像描述:模型能夠生成短篇和長篇的圖像說明,例如識別一張牛站在海灘上的圖片並提供詳細描述。
2. 光學字符識別(OCR):該模型可以從圖像中提取文字,識別標誌、標籤及文檔內容,為信息提取提供便利。
3. 圖像問答與目標檢測:用戶可通過上傳圖片並提出問題,模型會分析圖片並給出答案,此外,它還能準確識別圖像中的特定對象,如動物、車輛等。
值得一提的是,開發者可以在Kaggle 和Hugging Face 上下載這款模型的混合權重,便於進行進一步的實驗與開發。如果你對這款模型感興趣,可以通過Hugging Face 的演示平台進行探索,了解其強大的能力與應用潛力。
隨著PaliGemma2Mix 的推出,谷歌在視覺- 語言模型領域的研究又向前邁進了一步,期待這項技術能夠在實際應用中展現更大的價值。
技術報告:https://arxiv.org/abs/2412.03555







