Qventus raises US$105 million to promote AI innovation in the medical industry
382
English
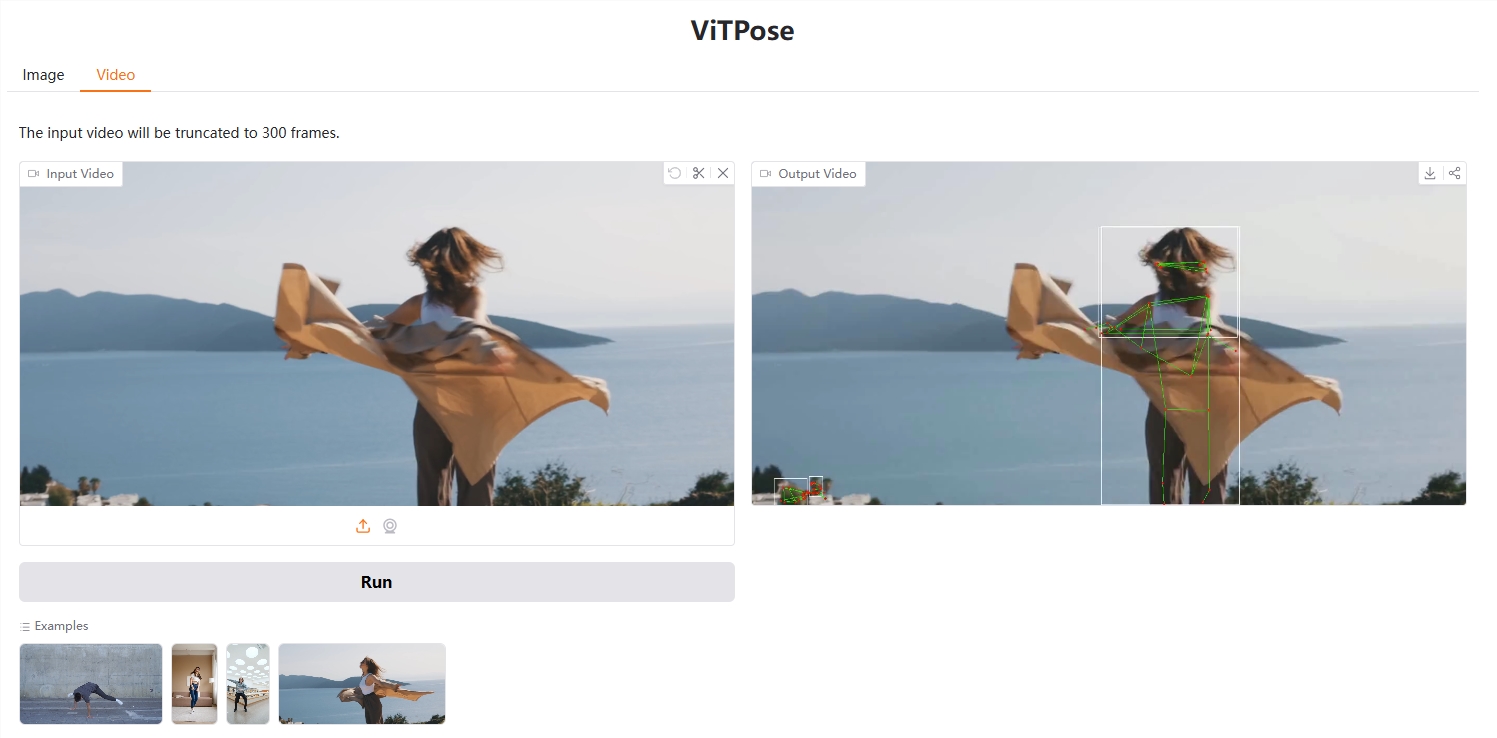
ViTPose is an open source action prediction model that is particularly good at recognizing human postures , just like it can understand what actions you are doing. The most powerful thing about this model is its simplicity and efficiency . It does not use a complex network structure, but directly uses a technology called visual Transformer .
At its core, ViTPose uses a purely visual Transformer , which acts like a powerful "skeleton" to extract key features in an image. It does not require the assistance of complex convolutional neural networks (CNN) like other models. Its structure is very simple, that is, multiple Transformers are layered together.
ViTPose models can be resized as needed. Like a stretchable ruler, you can control the size of your model by increasing or decreasing the number of Transformer layers to find a balance between performance and speed. You can also adjust the resolution of the input image and the model will adapt. In addition, it can process multiple data sets simultaneously, that is, you can use it to recognize data from different poses.
Despite its simple structure, ViTPose performs extremely well in human pose estimation . It achieves very good results on the famous MS COCO dataset, even surpassing many more complex models. This shows that simple models can be very powerful. Another feature of ViTPose is that it can transfer "knowledge" from large models to small models. It's like an experienced teacher can impart knowledge to students, so that small models can have the strength of large models.
ViTPose's code and models are open source, meaning anyone can use it for free and conduct research and development on it.
ViTPose is like a simple but powerful tool that helps computers understand human actions. Its advantages are simplicity, flexibility, efficiency and ease of learning. This makes it a very promising baseline model in the field of human pose estimation.
The model uses a Transformer layer to process image data and a lightweight decoder to predict key points. The decoder can use simple deconvolution layers or bilinear interpolation to upsample feature maps. ViTPose not only performs well on standard datasets, but also performs well in handling occlusions and different poses . It can be applied to various tasks such as human pose estimation, animal pose estimation, and facial key point detection .
demo:https://huggingface.co/spaces/hysts/ViTPose-transformers
Model: https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335
AI courses are suitable for people who are interested in artificial intelligence technology, including but not limited to students, engineers, data scientists, developers, and professionals in AI technology.
The course content ranges from basic to advanced. Beginners can choose basic courses and gradually go into more complex algorithms and applications.
Learning AI requires a certain mathematical foundation (such as linear algebra, probability theory, calculus, etc.), as well as programming knowledge (Python is the most commonly used programming language).
You will learn the core concepts and technologies in the fields of natural language processing, computer vision, data analysis, and master the use of AI tools and frameworks for practical development.
You can work as a data scientist, machine learning engineer, AI researcher, or apply AI technology to innovate in all walks of life.
