
AnimateDiff A1111 使用教學課程
1008
中文(新加坡)
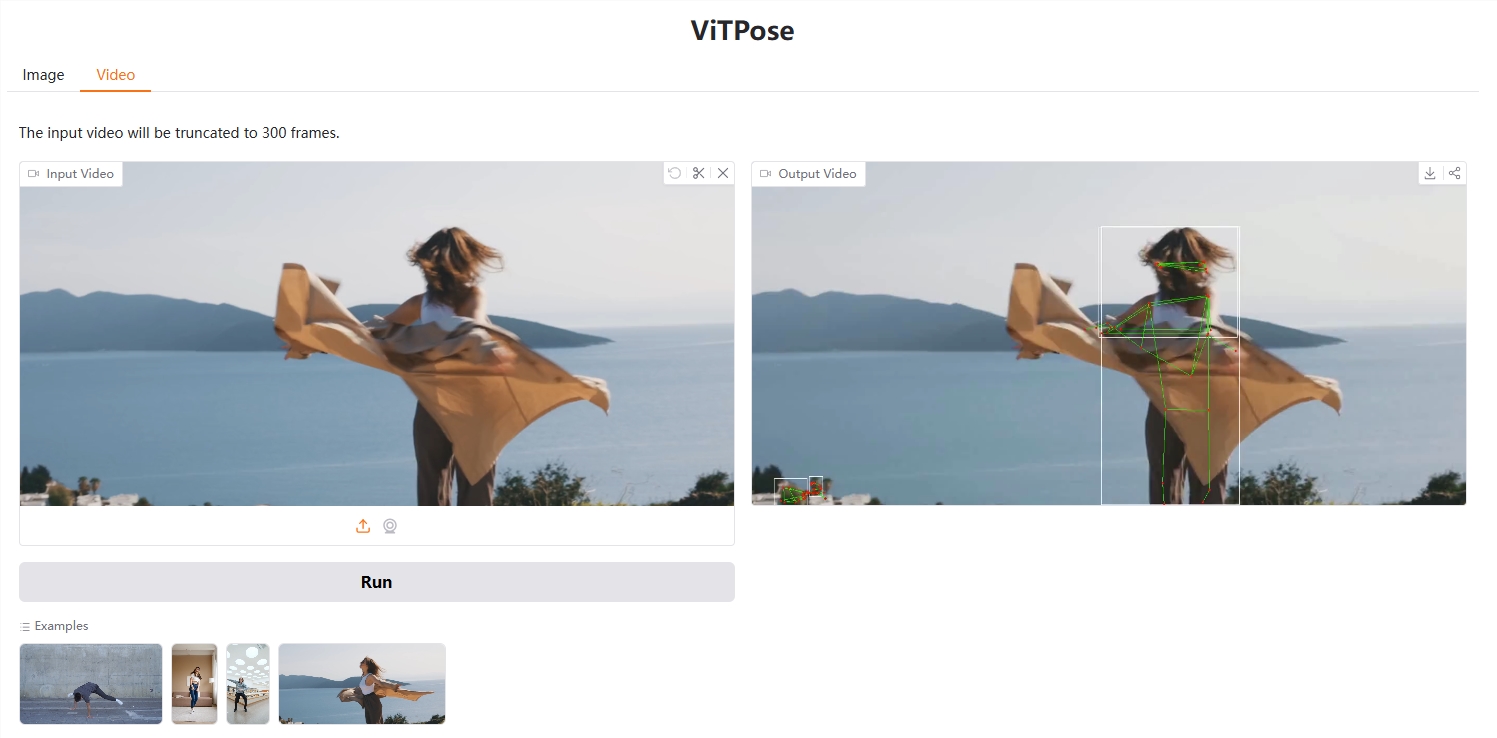
ViTPose是一個開源的動作預估模型,它特別擅長辨識人體姿態,就像能看懂你在做什麼動作一樣。 這個模型最厲害的地方在於它的簡潔和高效,它沒有採用複雜的網路結構,而是直接使用了一種叫做視覺Transformer的技術。
ViTPose 的核心是使用純粹的視覺Transformer ,這就像一個強大的“骨架”,可以提取圖像中的關鍵特徵。 它不像其他模型需要複雜的捲積神經網路(CNN)來輔助。 它的結構非常簡單,就是把多個Transformer層疊在一起。
ViTPose 模型可以根據需要調整大小。 就像一個可以伸縮的尺子,你可以透過增減Transformer層的數量來控制模型的大小,從而在效能和速度之間找到平衡。 你也可以調整輸入圖的分辨率,模型都能適應。 此外,它還可以同時處理多個資料集,也就是說,你可以用它來識別不同姿勢的資料。
儘管結構簡單,ViTPose在人體姿勢估計方面表現非常出色。 它在MS COCO這個著名的數據集上取得了非常好的成績,甚至超過了許多更複雜的模型。 這表明,簡單的模型也可以非常強大。 ViTPose 還有一個特點就是可以把「知識」從大的模型轉移到小的模型上。 這就像一個經驗豐富的老師可以把知識傳授給學生,讓小模型也能擁有大模型的實力。
ViTPose 的程式碼和模型都是開源的,這意味著任何人都可以免費使用它,並在此基礎上進行研究和開發。
ViTPose就像一個簡單卻強大的工具,它可以幫助電腦理解人類的動作。 它的優點在於簡單、靈活、有效率且易於學習。 這使得它成為人體姿態估計領域的一個非常有前途的基線模型。
該模型使用Transformer層處理影像數據,並使用輕量級的解碼器來預測關鍵點。 解碼器可以使用簡單的反捲積層或雙線性內插法來上取樣特徵圖。 ViTPose 不僅在標準資料集上表現良好,而且在處理遮蔽和不同姿勢的情況下也表現出色。 它可以應用於人體姿態估計,動物姿態估計,以及臉部關鍵點檢測等多種任務。
demo:https://huggingface.co/spaces/hysts/ViTPose-transformers
模型:https://huggingface.co/collections/usyd-community/vitpose-677fcfd0a0b2b5c8f79c4335
AI課程適合對人工智能技術感興趣的人,包括但不限於學生、工程師、數據科學家、開發者以及AI技術的專業人士。
課程內容從基礎到高級不等,初學者可以選擇基礎課程,逐步深入到更複雜的算法和應用。
學習AI需要一定的數學基礎(如線性代數、概率論、微積分等),以及編程知識(Python是最常用的編程語言)。
將學習自然語言處理、計算機視覺、數據分析等領域的核心概念和技術,掌握使用AI工具和框架進行實際開發。
您可以從事數據科學家、機器學習工程師、AI研究員、或者在各行各業應用AI技術進行創新。




