Manus Invitation Code Application Guide
1092
English
Recently, the successful launch of the VLM-R1 project has brought new dawn to this field. This project is the successful migration of the DeepSeek team's R1 approach in the visual language model, which means that AI's understanding of visual content will enter a completely new stage.
VLM-R1 was inspired by the R1 method open sourced by DeepSeek last year, which utilized GRPO (Generated Reward Processing Optimization) reinforcement learning technology and achieved excellent performance in plain text processing. Today, the VLM-R1 team has successfully applied this method to visual language models, opening up new worlds for the research of multimodal AI.

In the project's verification results, VLM-R1's performance was amazing. First of all, the R1 method shows extremely high stability in complex scenarios, which is particularly important in practical applications. Second, the model performs excellently in generalization capabilities. In comparison experiments, the performance of the traditional SFT (Supervised Fine-Tuning) model gradually declines as the number of training steps increases on the test data outside the field, while the R1 model can continue to improve during training. This shows that the R1 method allows the model to truly master the ability to understand visual content rather than relying solely on memory.
In addition, the VLM-R1 project is extremely difficult to get started, and the team provides developers with a complete training and evaluation process, so that developers can get started quickly. In a practical case, the model was asked to find the food with the highest protein content in a hearty food picture. The result was not only accurate answers, but also accurately boxes the egg cake with the highest protein content in the picture, showing its excellent visual understanding and reasoning ability.
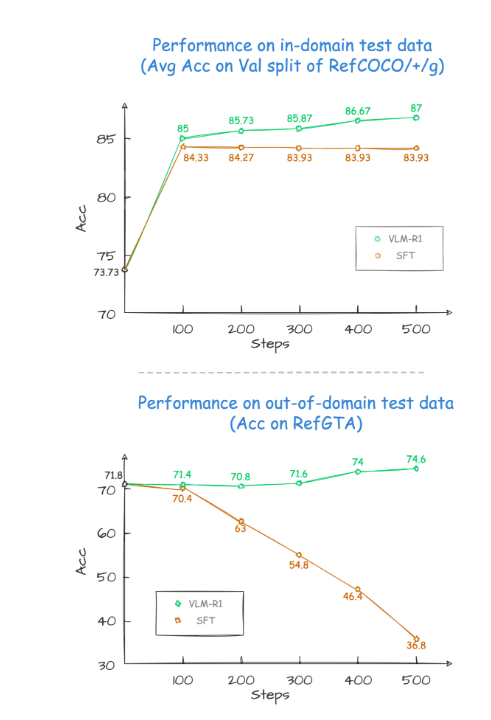
The successful launch of VLM-R1 not only proves the versatility of the R1 method, but also provides new ideas for the training of multimodal models, indicating the arrival of a new trend of visual language model training. What is even more exciting is that the project is completely open source and interested developers can find relevant information on GitHub.

In short, the advent of VLM-R1 has injected new vitality into the research of visual language models. We hope that more developers can participate and promote the continuous progress of multimodal AI technology.








