
Manus邀請碼申請攻略
1093
中文(繁體)
近日,VLM-R1項目的成功推出為這一領域帶來了新的曙光。該項目是DeepSeek 團隊的R1方法在視覺語言模型中的成功遷移,意味著AI 對視覺內容的理解將進入一個全新的階段。
VLM-R1的靈感源自於去年DeepSeek 開源的R1方法,該方法利用了GRPO(Generative Reward Processing Optimization)強化學習技術,在純文本處理上取得了優異的表現。如今,VLM-R1團隊將這一方法成功地應用於視覺語言模型,為多模態AI 的研究開闢了新天地。

在項目的驗證結果中,VLM-R1的表現令人驚艷。首先,R1方法在復雜場景下展現出了極高的穩定性,這在實際應用中顯得尤為重要。其次,該模型在泛化能力方面表現卓越。在對比實驗中,傳統的SFT(Supervised Fine-Tuning)模型在領域外的測試數據上隨著訓練步數的增加,其性能卻逐漸下滑,而R1模型則能在訓練中不斷提升。這表明,R1方法使得模型真正掌握了理解視覺內容的能力,而非僅僅依賴於記憶。
此外,VLM-R1項目的上手難度極低,團隊為開發者提供了完整的訓練和評估流程,讓開發者可以快速上手。在一次實際案例中,模型被要求找出一張豐盛美食圖片中蛋白質含量最高的食物,結果不僅回答準確,還在圖片中精準框選出蛋白質含量最高的雞蛋餅,展示了其出色的視覺理解和推理能力。
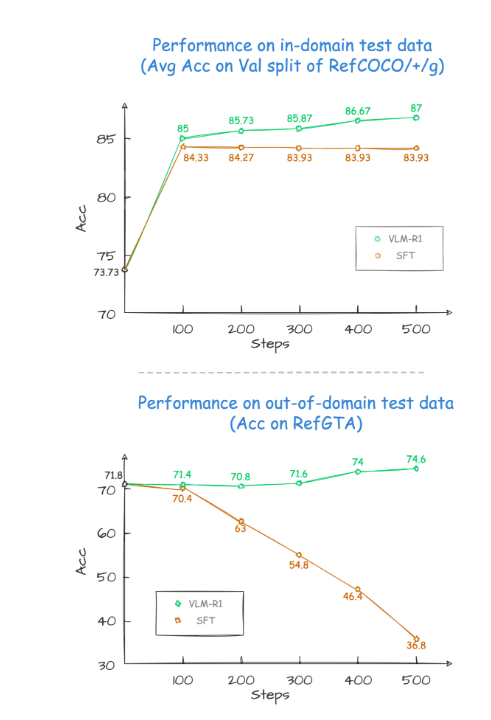
VLM-R1的成功推出不僅證明了R1方法的通用性,也為多模態模型的訓練提供了新思路,預示著一種全新的視覺語言模型訓練潮流的到來。更令人振奮的是,該項目完全開源,感興趣的開發者可以在GitHub 上找到相關資料。

總之,VLM-R1的問世為視覺語言模型的研究注入了新的活力,期待更多開發者能夠參與其中,推動多模態AI 技術的不斷進步。







