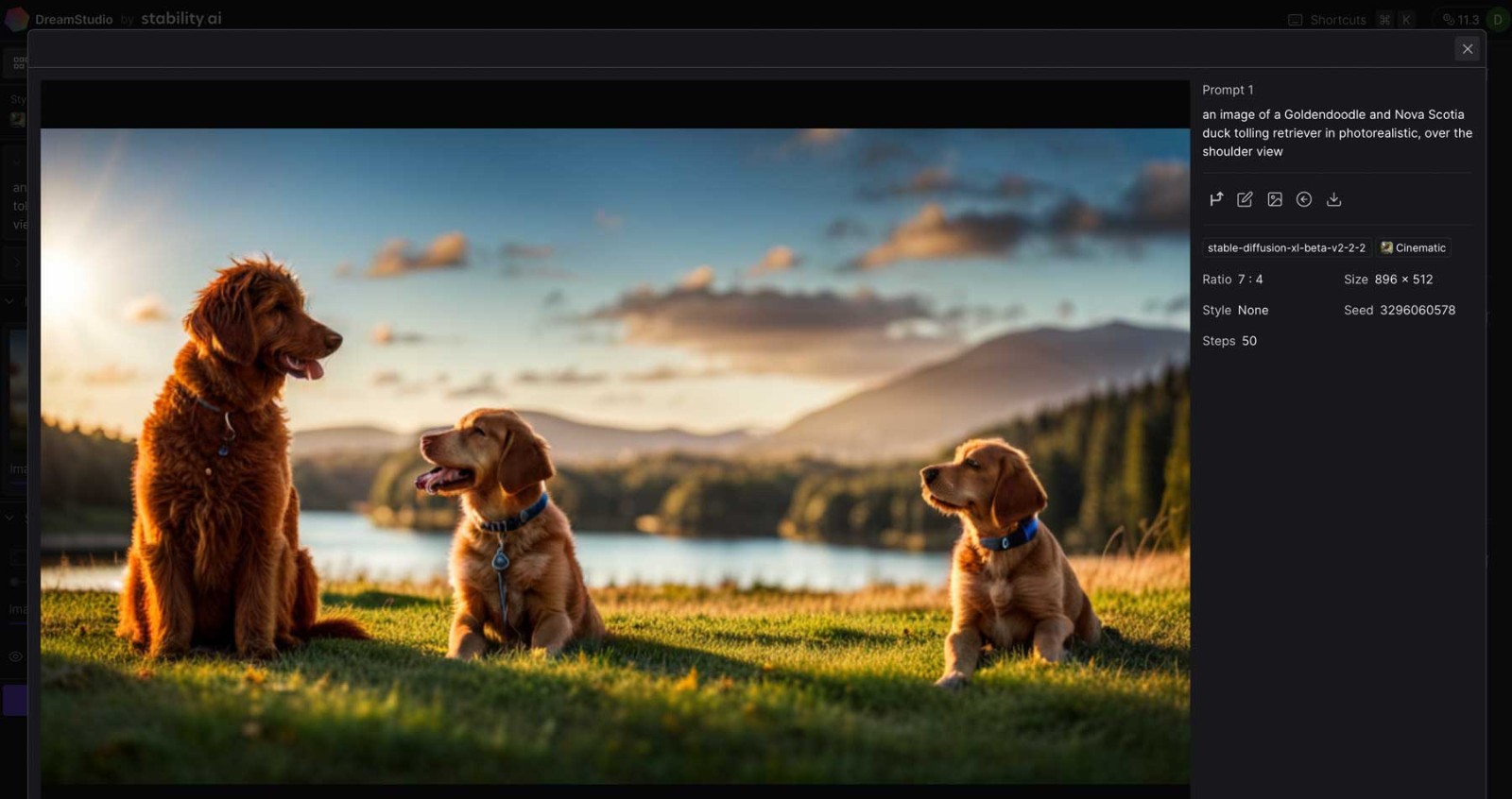
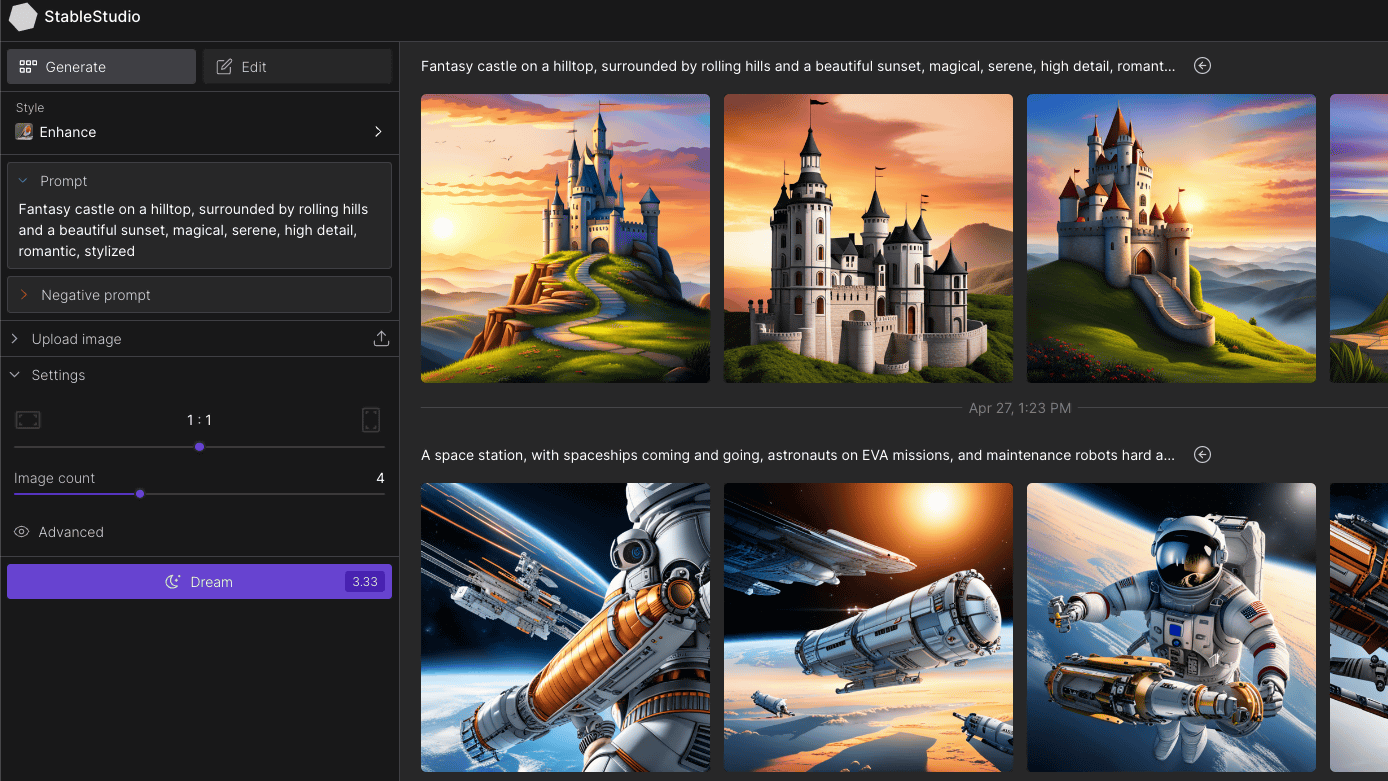
Stability AI (Stable Diffusion系列)
根據使用者提供的文字描述產生高品質的圖像,並且具備靈活的控制選項,適用於藝術創作、視覺設計、廣告製作等多個領域。
中文(繁體)
Stability AI是一家專注於開發人工智慧生成內容的公司,其最著名的產品之一是Stable Diffusion ,一個強大的圖像生成模型。 Stable Diffusion 可以根據使用者提供的文字描述產生高品質的影像,並且具備靈活的控制選項,適用於藝術創作、視覺設計、廣告製作等多個領域。
Stability AI 提供了一個基於REST API 的接口,使開發者可以透過簡單的HTTP 請求將其強大的圖像生成能力整合到各種應用中。無論是生成抽象藝術作品、插畫,或是創作逼真的場景,Stable Diffusion 都能輕鬆應付。透過這篇教學,我們將介紹如何註冊並使用Stability AI 提供的API,幫助你開始使用Stable Diffusion來進行影像生成。
接下來的部分將詳細說明如何透過Stability AI API 使用Stable Diffusion 模型產生圖像,並提供了完整的程式碼範例,幫助你迅速入門。
1. 註冊並取得API金鑰
要使用Stability AI API (例如用於Stable Diffusion模型產生映像),首先需要在其平台上註冊並取得API金鑰。以下是步驟:
請造訪Stability AI官方網站: https://stability.ai
建立帳戶並登入。
進入開發者控制台,找到API金鑰選項。
產生並複製API金鑰(在後續請求中需要使用)。
2. 透過REST API 呼叫Stable Diffusion 產生映像
Stability AI 提供基於REST API 的服務來產生影像。你可以使用以下範例程式碼呼叫API 建立映像。
請求URL
bash複製程式碼POST https://api.stability.ai/v1/generate
請求頭
需要在請求中加入你的API金鑰,通常放在Authorization請求頭中:
http複製程式碼Authorization: Bearer YOUR_API_KEY
請求體
請求體應包含以下欄位:
model :模型名稱,如"stable-diffusion-v2-1"
prompt :描述產生圖像的文字提示。
num_images :需要產生的圖像數量,通常是1張或更多。
width :產生影像的寬度(通常是512或更大,取決於API支援的尺寸)。
height :產生影像的高度(同樣,通常是512或更大)。
範例POST 請求
python複製程式碼import requestsimport json# 設定API 金鑰api_key = 'YOUR_API_KEY'# 請求URLurl = "https://api.stability.ai/v1/generate"# 請求頭headers = { "Authorization": f"Bearer {api_key }", "Content-Type": "application/json"}# 請求體,包含產生影像的詳細資料data = { "model": "stable-diffusion-v2-1", "prompt": "A futuristic city with flying cars and neon lights", "num_images": 1, "width": 512, "height": 512, "steps ": 50, # 可選,影響生成的影像品質和細節"seed": 42 #可選,設定隨機種子來重現產生的圖像}# 發送POST 請求response = requests.post(url, headers=headers, data=json.dumps(data))# 檢查回應狀態if response.status_code == 200: # 解析並儲存圖片result = response.json()
image_url = result['images'][0]['url']
image_data = requests.get(image_url).content with open("generated_image.png", "wb") as f:
f.write(image_data) print("Image saved as generated_image.png")else: print("Error:", response.text)3. 參數說明
model : 使用的模型名稱。例如可以選擇"stable-diffusion-v2-1" 或其他支援的模型版本。
prompt : 產生圖像的描述文字(例如「一個充滿霓虹燈的未來城市」)。
num_images : 產生的圖像數量,通常設定為1。
width和height : 輸出影像的尺寸,通常選擇512x512或更高(例如768x768)。
steps : 產生影像時的迭代步數,更多的步數通常會帶來更高品質的影像(一般設定在20到100之間)。
seed : 產生影像時使用的隨機種子,可以控制影像的可複現性。預設是隨機的,但你可以設定一個特定的數值以確保產生的圖像相同。
4. 範例響應
如果請求成功,API 會傳回回應對象,包含產生的影像的URL。以下是一個回應範例:
json複製程式碼{
"images": [
{
"url": "https://stability.ai/generate/image1.png"
}
]}你可以使用該URL 來下載產生的圖像。
5. 錯誤處理
如果請求出錯,回應中會包含錯誤訊息,你可以透過狀態碼或傳回的錯誤訊息來診斷問題。例如,錯誤代碼為400 可能表示請求格式不正確,403 表示API金鑰無效或權限問題。