
Manus邀請碼申請攻略
1093
中文(繁體)
近日,Vectara 發布了一份名為“幻覺排行榜” 的報告,比較了不同大型語言模型(LLM)在總結短文檔時產生幻覺的表現。這份排行榜利用了Vectara 的Hughes 幻覺評估模型(HHEM-2.1),該模型定期更新,旨在評估這些模型在摘要中引入虛假信息的頻率。根據最新數據,報告指出了一系列流行模型的幻覺率、事實一致性率、應答率以及平均摘要長度等關鍵指標。
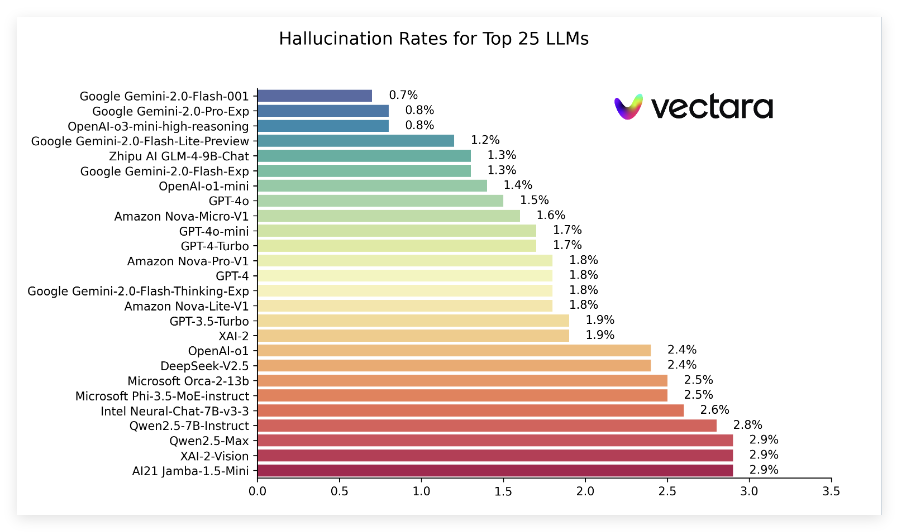
在最新的排行榜中,谷歌的Gemini2.0系列表現出色,尤其是Gemini-2.0-Flash-001,以0.7% 的低幻覺率位居榜首,顯示出其在處理文檔時幾乎沒有引入虛假信息。此外,Gemini-2.0-Pro-Exp 和OpenAI 的o3-mini-high-reasoning 模型分別以0.8% 的幻覺率緊隨其後,表現同樣不俗。
報告還顯示,儘管許多模型的幻覺率有所上升,但大部分仍保持在一個較低的水平,且多模型的事實一致性率均在95% 以上,表明它們在確保信息真實方面的能力相對強勁。特別值得注意的是,模型的應答率普遍較高,絕大多數模型的應答率接近100%,這意味著它們在理解和回應問題時表現出色。
另外,排行榜還提及了不同模型的平均摘要長度,說明模型在信息濃縮方面的能力差異。總體來看,該排行榜不僅為研究者和開發者提供了重要的參考數據,也為普通用戶了解當前大型語言模型的表現提供了便利。
具體排名入口:https://github.com/vectara/hallucination-leaderboard







