
如何訓練SDXL LoRA 模型
1006
中文(新加坡)
隨著大語言模型(LLM)在現代人工智慧應用中的廣泛應用,諸如聊天機器人和程式碼產生器等工具依賴這些模型的能力。然而,隨之而來的推理過程中的效率問題也日益突出。
尤其是在處理注意力機制時,如FlashAttention 和SparseAttention,面對多樣化的工作負載、動態輸入模式以及GPU 資源限制時,往往顯得力不從心。這些挑戰加上高延遲和記憶體瓶頸,迫切需要更有效率、靈活的解決方案,以支援可擴展和響應迅速的LLM 推理。
為了解決這個問題,來自華盛頓大學、NVIDIA、Perplexity AI 和卡內基美隆大學的研究人員共同開發了FlashInfer,這是一個專門為LLM 推理設計的人工智慧庫和核心生成器。 FlashInfer 提供了高效能的GPU 核心實現,涵蓋多種注意力機制,包括FlashAttention、SparseAttention、PageAttention 及取樣。其設計理念強調靈活性和效率,旨在應對LLM 推理服務的關鍵挑戰。
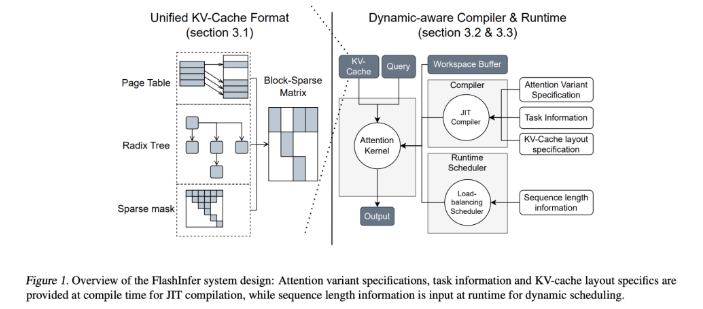
FlashInfer 的技術特性包括:
1. *全面的注意力核心:支援多種注意力機制,包括預先填充、解碼和追加註意力,相容於各種KV-cache 格式,提升單一請求和批次服務場景的效能。
2. *優化的共享前綴解碼:透過分組查詢注意力(GQA)和融合的旋轉位置嵌入(RoPE)注意力,FlashInfer 實現了顯著的速度提升,例如在長提示解碼方面,比vLLM 的Page Attention 實現快31倍。
3. 動態負載平衡調度:FlashInfer 的調度器能依輸入變化動態調整,減少GPU 空閒時間,確保高效率利用。它與CUDA Graphs 的兼容性進一步提升了在生產環境中的適用性。
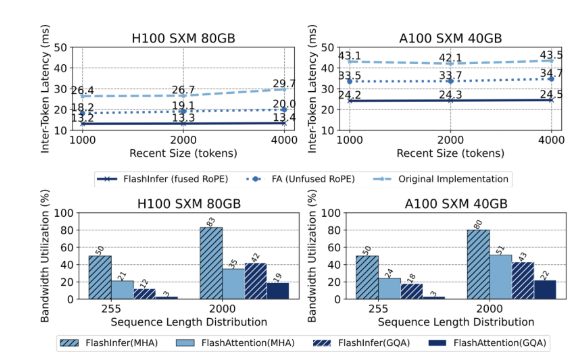
在效能方面,FlashInfer 在多個基準測試中表現出色,顯著減少了延遲,特別是在處理長上下文推理和並行生成任務中表現出色。在NVIDIA H100GPU 上,FlashInfer 在平行產生任務中實現了13-17% 的速度提升。其動態調度器和最佳化的內核顯著改善了頻寬和FLOP 利用率,特別是在序列長度不均或均勻的情況下。
FlashInfer 為LLM 推理挑戰提供了切實可行且有效率的解決方案,大幅提升了效能和資源利用效率。其靈活的設計和整合能力,使其成為推動LLM 服務框架發展的重要工具。作為一個開源項目,FlashInfer 鼓勵研究界的進一步合作與創新,確保在人工智慧基礎設施領域的持續改進和適應新興挑戰。
專案入口:https://github.com/flashinfer-ai/flashinfer
AI課程適合對人工智能技術感興趣的人,包括但不限於學生、工程師、數據科學家、開發者以及AI技術的專業人士。
課程內容從基礎到高級不等,初學者可以選擇基礎課程,逐步深入到更複雜的算法和應用。
學習AI需要一定的數學基礎(如線性代數、概率論、微積分等),以及編程知識(Python是最常用的編程語言)。
將學習自然語言處理、計算機視覺、數據分析等領域的核心概念和技術,掌握使用AI工具和框架進行實際開發。
您可以從事數據科學家、機器學習工程師、AI研究員、或者在各行各業應用AI技術進行創新。




