
Manus邀請碼申請攻略
1093
中文(繁體)
近日,由Arc Institute 和Nvidia 聯合開發的Evo2生物AI 模型正式發布。這一基礎模型基於超過10萬種生物的DNA 數據,旨在深度解碼生物學中的各種複雜現象。 Evo2能夠在不同生物體的基因序列中識別出研究者們需要花費多年時間才能發現的模式,極大提升了疾病相關突變的識別能力,並可以設計出與簡單細菌相當的全新基因組。
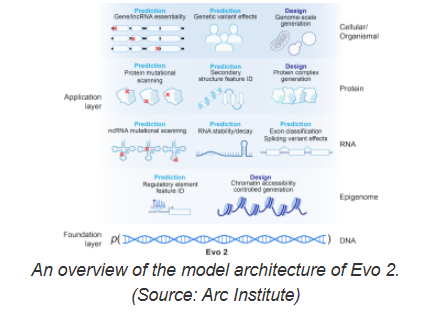
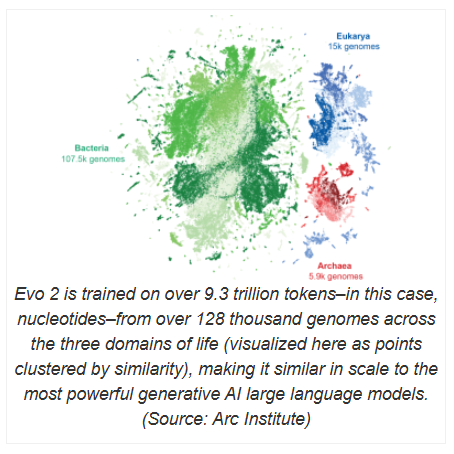
Evo2的訓練涉及超過93萬億個核苷酸的處理,遠超其前身Evo1。其開發團隊來自Nvidia 和位於加州帕洛阿爾託的非營利生物醫學研究機構Arc Institute,還與斯坦福大學、加州大學伯克利分校和加州大學舊金山分校的研究人員密切合作。 Evo2不僅具備強大的計算能力,還在透明性和可解釋性方面做出了積極探索。為了使科學研究更加開放,研究團隊還公開了Evo2的訓練數據、代碼和模型權重,標誌著其成為迄今為止最大規模的完全開源生物AI 模型。
Patrick Hsu,Arc Institute 的共同創始人及UC Berkeley 的助理教授表示,Evo2的開發是生成生物學領域的一次重要突破。通過這項技術,機器能夠“閱讀”、“寫作” 和“思考” 核苷酸的語言,推動了生物研究的進展。 Evo2的訓練能力與大規模語言模型相媲美,顯示出在預測疾病突變及設計潛在人工生命方面的強大潛力。
此外,Evo2還能夠為生物療法的設計提供新思路,例如針對特定細胞類型激活的基因治療,以減少副作用並提高治療精度。 Evo2的開發不僅是在技術上的突破,同時也對生物學的理解產生了深遠影響。
在研究人員確保模型的負責任開發時,特意排除了會感染人類及其他復雜生物的病原體數據。 Nvidia 的數字生物學總監Anthony Costa 表示,Evo2突破了生物基礎模型的局限,為全球科學家提供了強大的合作工具,以應對人類面臨的重大健康和疾病挑戰。







