中文(繁體)
中文(繁體)
文生圖(Text to Image) ,是AI 繪圖中的基礎流程,通過輸入文本描述來生成對應的圖片,它的核心是 擴散模型。
在文生圖過程中我們需要以下條件:
1.畫家: 繪圖模型
2.畫布: 潛在空間
3.**對畫面的要求(提示詞):**提示詞,包括正向提示詞(希望在畫面中出現的元素)和負向提示詞(不希望在畫面中出現的元素)
這個文本到圖片圖片生成過程,可以簡單理解成你把你的繪圖要求(正向提示詞、負向提示詞)告訴一個畫家(繪圖模型),畫家會根據你的要求,畫出你想要的內容。
請確保你已經在 ComfyUI/models/checkpoints 文件夾至少有一個SD1.5 的模型文件。
你可以使用下面的這些模型:
1. v1-5-pruned-emaonly-fp16.safetensors
3. Anything V5
請下載下面的圖片,並將圖片拖入ComfyUI 的界面中,或者使用菜單 工作流(Workflows) -> 打開(Open) 打開這個圖片以加載對應的workflow

也可以從菜單 工作流(Workflows) -> 瀏覽工作流示例(Browse example workflows) 中選擇 Text to Image 工作流
在完成了對應的繪圖模型安裝後,請參考下圖步驟加載對應的模型,並進行第一次圖片的生成
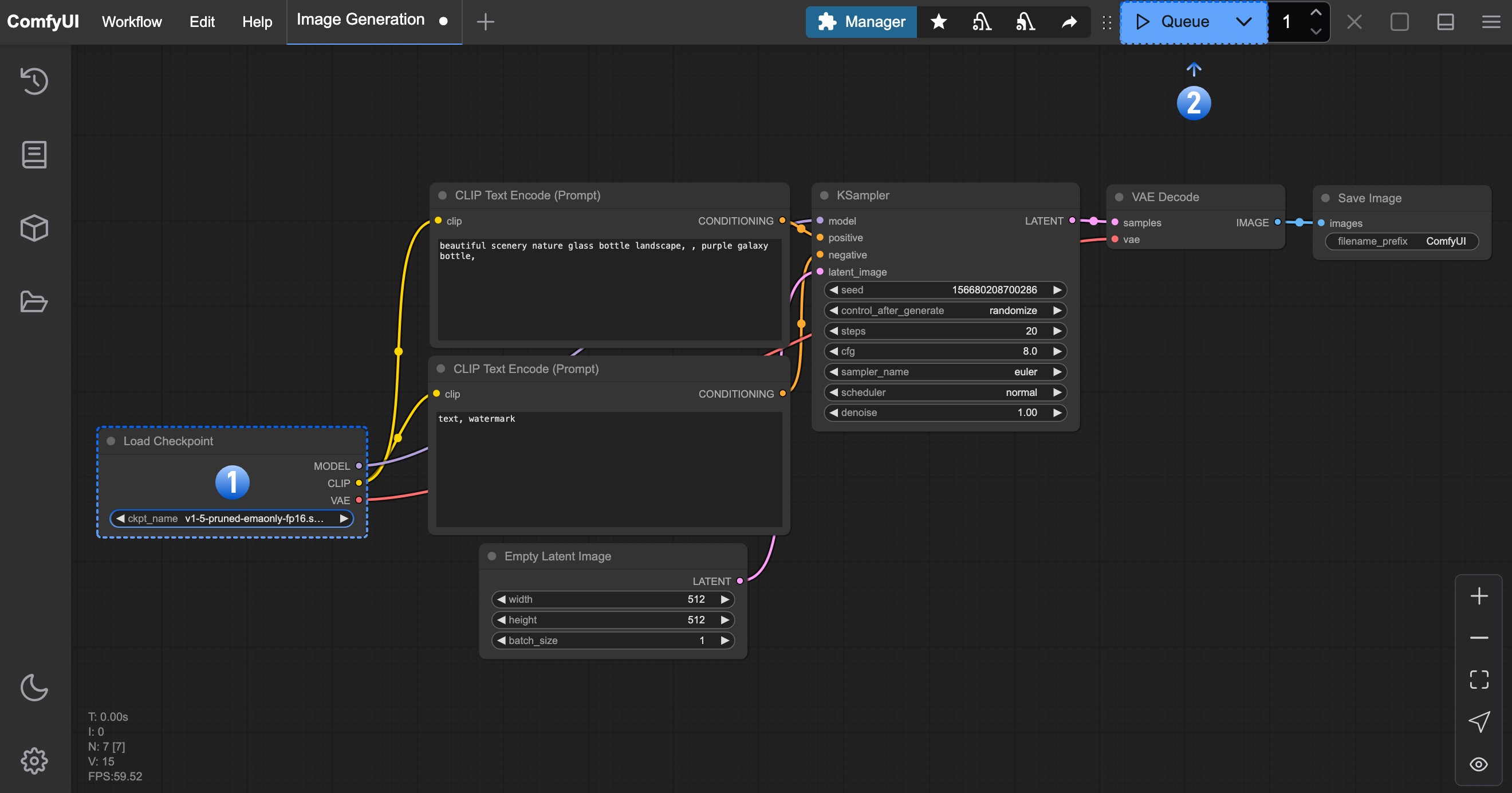
請對應圖片序號,完成下面操作
1.請在Load Checkpoint 節點使用箭頭或者點擊文本區域確保 v1-5-pruned-emaonly-fp16.safetensors 被選中,且左右切換箭頭不會出現null 的文本
2.點擊 Queue 按鈕,或者使用快捷鍵 Ctrl + Enter(回車) 來執行圖片生成
等待對應流程執行完成後,你應該可以在界面的**保存圖像(Save Image)**節點中看到對應的圖片結果,可以在上面右鍵保存到本地
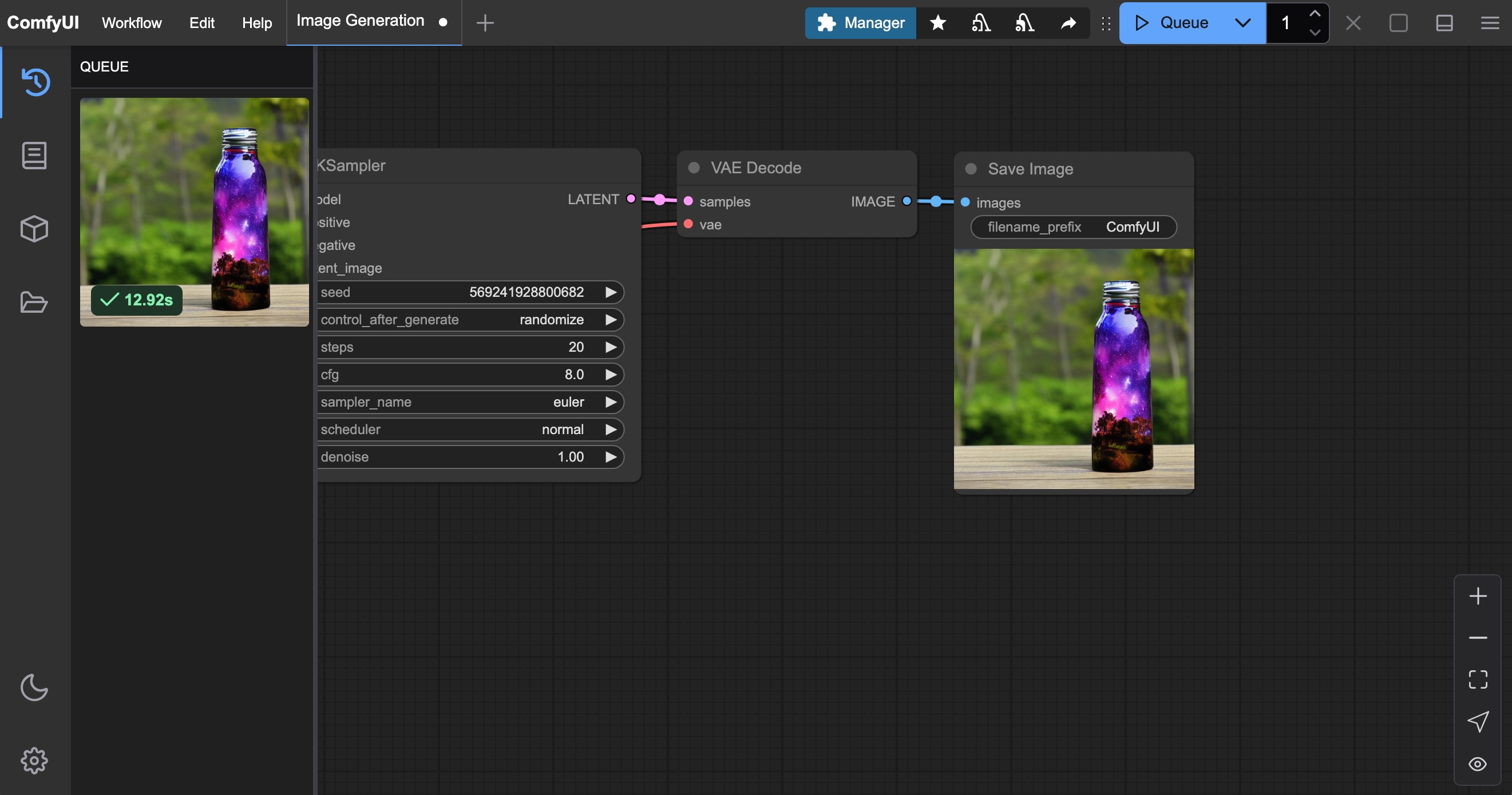
你可以嘗試修改CLIP Text Encoder處的文本
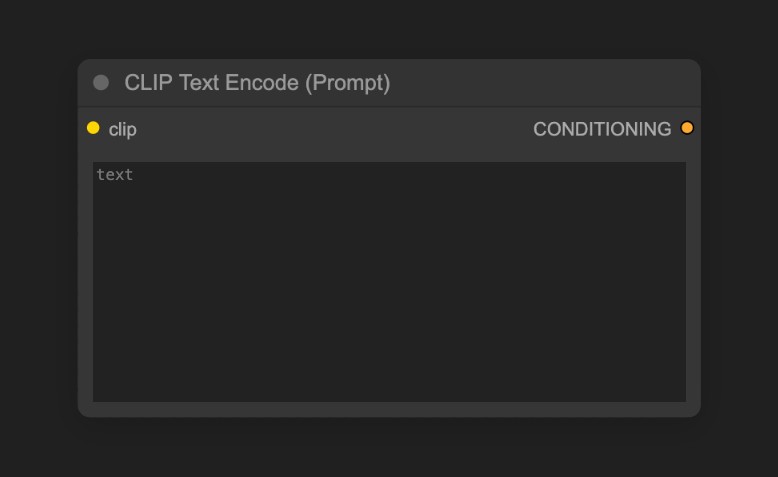
其中連接到KSampler 節點的Positive為正向提示詞,連接到KSampler 節點的Negative為負向提示詞
下面是針對SD1.5 模型的一些簡單提示詞原則
盡量使用英文
提示詞之間使用英文逗號 , 隔開
盡量使用短語而不是長句子
使用更具體的描述
可以使用類似 (golden hour:1.2) 這樣的表達來提升特定關鍵詞的權重,這樣它在畫面中出現的概率會更高,1.2 為權重,golden hour 為關鍵詞
可以使用類似 masterpiece, best quality, 4k 等關鍵詞來提升生成質量
下面是幾組不同的prompt 示例,你可以嘗試使用這些prompt 來查看生成的效果,或者使用你自己的prompt 來嘗試生成
1. 二次元動漫風格
正向提示詞:
anime style, 1girl with long pink hair, cherry blossom background, studio ghibli aesthetic, soft lighting, intricate detailsmasterpiece, best quality, 4k
負向提示詞:
low quality, blurry, deformed hands, extra fingers
2. 寫實風格
正向提示詞:
(ultra realistic portrait:1.3), (elegant woman in crimson silk dress:1.2),full body, soft cinematic lighting, (golden hour:1.2),(fujifilm XT4:1.1), shallow depth of field,(skin texture details:1.3), (film grain:1.1),gentle wind flow, warm color grading, (perfect facial symmetry:1.3)
負向提示詞:
(deformed, cartoon, anime, doll, plastic skin, overexposed, blurry, extra fingers)
3. 特定藝術家風格
正向提示詞:
fantasy elf, detailed character, glowing magic, vibrant colors, long flowing hair, elegant armor, ethereal beauty, mystical forest, magical aura, high detail, soft lighting, fantasy portrait, Artgerm style
負向提示詞:
blurry, low detail, cartoonish, unrealistic anatomy, out of focus, cluttered, flat lighting
整個文生圖的過程,我們可以理解成是擴散模型的反擴散過程,我們下載的v1-5-pruned-emaonly-fp16.safetensors是一個已經訓練好的可以 從純高斯噪聲生成目標圖片的模型,我們只需要輸入我們的提示詞,它就可以通隨機的噪聲降噪生成目標圖片。

我們可能需要了解下兩個概念,
1.潛在空間:潛在空間(Latent Space)是擴散模型中的一種抽像數據表示方式,通過把圖片從像素空間轉換為潛在空間,可以減少圖片的存儲空間,並且可以更容易的進行擴散模型的訓練和減少降噪的複雜度,就像建築師設計建築時使用藍圖(潛在空間)來進行設計,而不是直接在建築上進行設計(像素空間),這種方式可以保持結構特徵的同時,又大幅度降低修改成本
2.像素空間:像素空間(Pixel Space)是圖片的存儲空間,就是我們最終看到的圖片,用於存儲圖片的像素值。
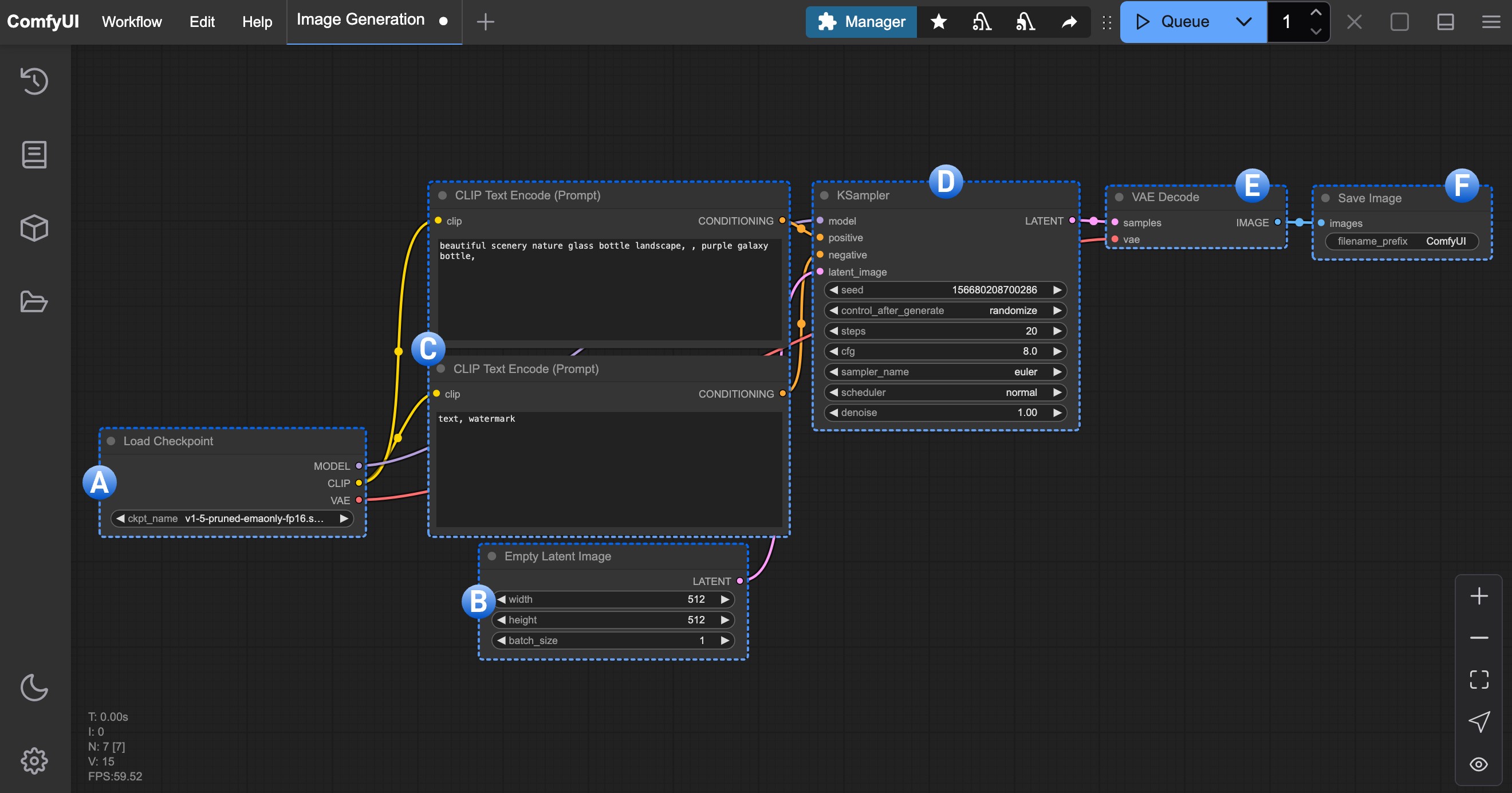
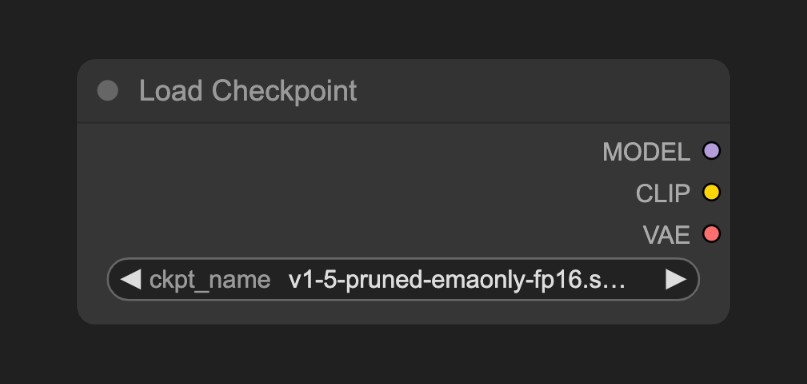
這個節點通常用於加載繪圖模型, 通常 checkpoint 中會包含 MODEL(UNet)、CLIP 和 VAE 三個組件
1.MODEL(UNet):為對應模型的 UNet 模型, 負責擴散過程中的噪聲預測和圖像生成,驅動擴散過程
2.CLIP:這個是文本編碼器,因為模型並不能直接理解我們的文本提示詞(prompt),所以需要將我們的文本提示詞(prompt)編碼為向量,轉換為模型可以理解的語義向量
3.VAE:這個是變分自編碼器,我們的擴散模型處理的是潛在空間,而我們的圖片是像素空間,所以需要將圖片轉換為潛在空間,然後進行擴散,最後將潛在空間轉換為圖片
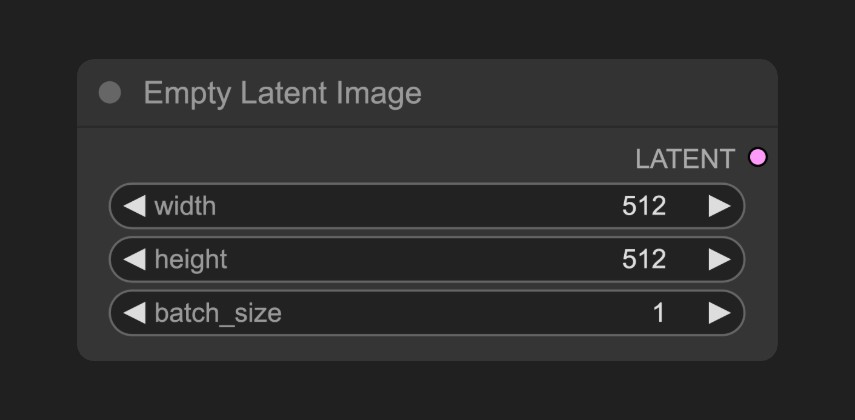
定義一個潛在空間(Latent Space),它輸出到KSampler 節點,空Latent圖像節點構建的是一個 純噪聲的潛在空間
它的具體的作用你可以理解為定義畫布尺寸的大小,也就是我們最終生成圖片的尺寸
用於編碼提示詞,也就是輸入你對畫面的要求
1.連接到 KSampler 節點的 Positive 條件輸入的為正向提示詞(希望在畫面中出現的元素)
2.連接到 KSampler 節點的 Negative 條件輸入的為負向提示詞(不希望在畫面中出現的元素)
對應的提示詞被來自 Load Checkpoint 節點的 CLIP 組件編碼為語義向量,然後作為條件輸出到KSampler 節點
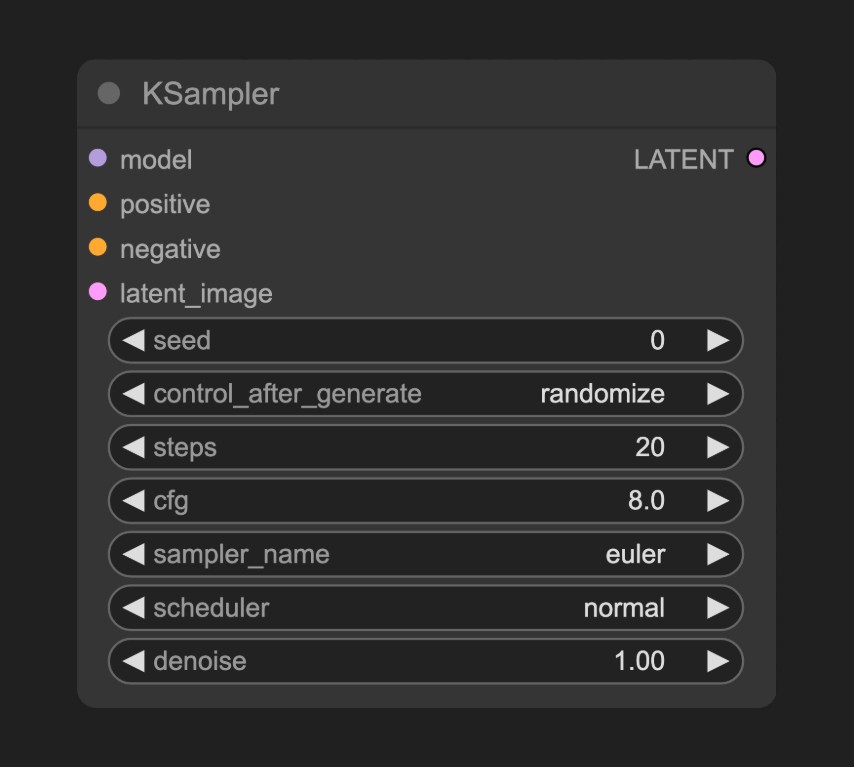
K 採樣器 是整個工作流的核心,整個噪聲降噪的過程都在這個節點中完成,並最後輸出一個潛空間圖像

KSampler 節點的參數說明如下
| 參數名稱 | 描述 | 作用 |
|---|---|---|
| model | 去噪使用的擴散模型 | 決定生成圖像的風格與質量 |
| positive | 正向提示詞條件編碼 | 引導生成包含指定元素的內容 |
| negative | 負向提示詞條件編碼 | 抑制生成不期望的內容 |
| latent_image | 待去噪的潛在空間圖像 | 作為噪聲初始化的輸入載體 |
| seed | 噪聲生成的隨機種子 | 控制生成結果的隨機性 |
| control_after_generate | 種子生成後控制模式 | 決定多批次生成時種子的變化規律 |
| steps | 去噪迭代步數 | 步數越多細節越精細但耗時增加 |
| cfg | 分類器自由引導係數 | 控制提示詞約束強度(過高導致過擬合) |
| sampler_name | 採樣算法名稱 | 決定去噪路徑的數學方法 |
| scheduler | 調度器類型 | 控制噪聲衰減速率與步長分配 |
| denoise | 降噪強度係數 | 控制添加到潛在空間的噪聲強度,0.0保留原始輸入特徵,1.0為完全的噪聲 |
在KSampler 節點中,潛在空間使用 seed 作為初始化參數構建隨機的噪聲,語義向量 Positive 和 Negative 會作為條件輸入到擴散模型中
然後根據 steps 參數指定的去噪步數,進行去噪,每次去噪會根據 denoise 參數指定的降噪強度係數,對潛在空間進行降噪,並生成新的潛在空間圖像
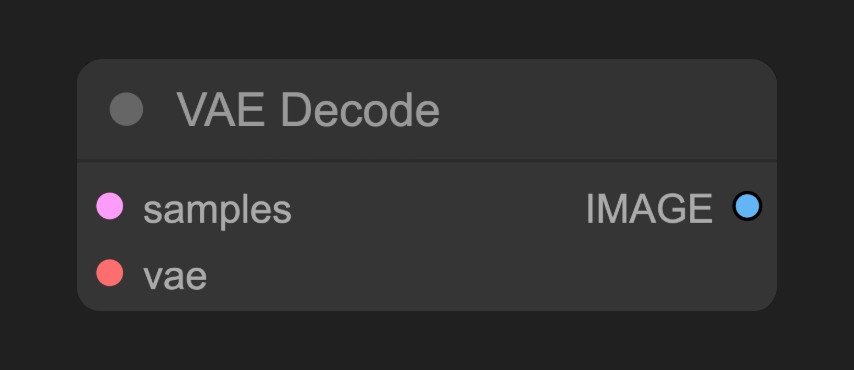
將 K 採樣器(KSampler) 輸出的潛在空間圖像轉換為像素空間圖像
預覽並保存從潛空間解碼的圖像,並保存到本地ComfyUI/output文件夾下
SD1.5(Stable Diffusion 1.5) 是一個由Stability AI開發的AI繪圖模型,Stable Diffusion系列的基礎版本,基於 512×512 分辨率圖片訓練,所以其對 512×512 分辨率圖片生成支持較好,體積約為4GB,可以在**消費級顯卡(如6GB顯存)**上流暢運行。目前SD1.5 的相關周邊生態非常豐富,它支持廣泛的插件(如ControlNet、LoRA)和優化工具。 作為AI繪畫領域的里程碑模型,SD1.5憑藉其開源特性、輕量架構和豐富生態,至今仍是最佳入門選擇。儘管後續推出了SDXL/SD3等升級版本,但其在消費級硬件上的性價比仍無可替代。
發佈時間:2022年10月
核心架構:基於Latent Diffusion Model (LDM)
訓練數據:LAION-Aesthetics v2.5數據集(約5.9億步訓練)
開源特性:完全開源模型/代碼/訓練數據
模型優勢:
輕量化:體積小,僅4GB 左右,在消費級顯卡上流暢運行
使用門檻低:支持廣泛的插件和優化工具
生態成熟:支持廣泛的插件和優化工具
生成速度快:在消費級顯卡上流暢運行
模型局限:
細節處理:手部/複雜光影易畸變
分辨率限制:直接生成1024x1024質量下降
提示詞依賴:需精確英文描述控制效果